

Has an LLM Cultural Victory Already Been Achieved?
The Deepseek Conundrum


There has been huge talk recently regarding the performance-to-cost ratio of Deepseek’s LLM products, particularly their new reasoning model causing OpenAI’s reasoning-based moat to partially evaporate. Companies like Perplexity, Cursor & Co (including most YC startups these days) have been quick to integrate these with good reason, most likely saving themselves some money in the process. Most likely, Deepseek have generated a large amount of synthetic data from state-of-the-art models such as o1, or by cleverly prompting non-reasoning models such as 4o or their own V3. As an accepted practice, this is the core idea behind recursive improvement, so no harm done. And if OpenAI and others have priced their API correctly, then they’re also set to gain. Everyone’s a winner (spoilers, they are not), and we’ll only see more of this in the future.
I personally have been benchmarking LLMs to make decisions within Bayesian optimisation loops, in a bid to eke out some in-silico performance (for functions that behave reasonably). Every time I reach a natural conclusion to benchmarking where the next best model is too expensive to run on my test suite, someone pushes the Pareto front a little bit more in the direction of ‘time to stop writing that preprint and get some more results’. The impact of these models will be never be as small as it is now.
A obvious point that people still seem to find surprising is that Deepseek censor inputs and outputs to align with the views of the Chinese government, specifically (again, rather obviously) events surrounding Tiananmen Square. Given Deepseek’s servers will be in China, it’s an aspect of communication that the Government has enforced for practically as long as the internet has existed.
I consider this very much a non-story. What I find more interesting are what underlying values the LLM has. These go deeper than specific phrases or keywords and enter into the murky realm of thoughts and feelings.
I’ve written previously about values and LLMs, and how datasets not only contain a representation of language as a structure, but the values of those who have written or collated the text. In effect, we shouldn’t be surprised when models from other countries appear misaligned to our own, Western, benchmarks, if they have been trained on distinct datasets. Even with learned translation, we shouldn’t be surprised if we don’t find them particularly revealing, especially as we approach concepts such as ‘intelligence’. Likewise, as we in the West share more common values with current SOTA LLMs than those elsewhere, we shouldn’t be surprised if they are found less appealing or useful in other countries. This is a hidden upside to the development of LLMs, they are implicitly more accessible, beneficial and provide more productivity to those with similar values.
So what work has already been done in this field? The preprint “LLM-GLOBE: A Benchmark Evaluating the Cultural Values Embedded in LLM Output” presents a methodology based from a framework devised in 2004. Outputs from LLMs are ranked using an automated ‘jury’ across a number of criteria including “Institutional Collectivism” and “Future Orientation” etc… It’s a logical extension to the original methodology, and I won’t argue against this work or the proceeding work on GLOBE (for now). What I care about are the results. So after all that, we have a brand new suite that measures exactly what we’re interested in. Not censorship, or language, but values. Time to reveal the results…
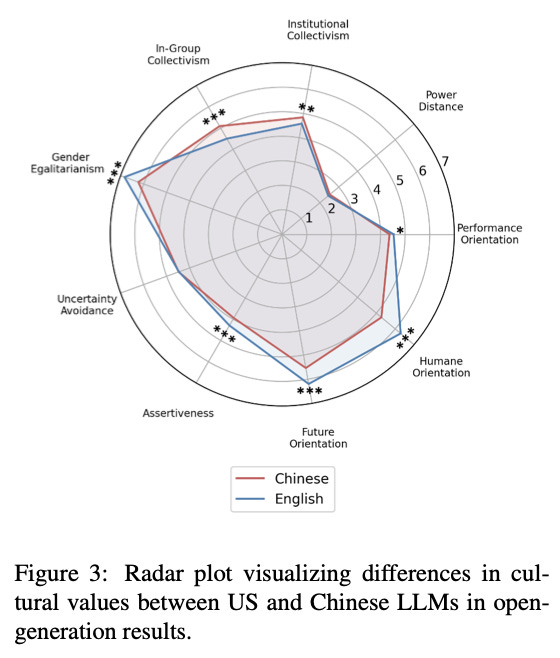
Oh. They look strikingly similar. So Chinese LLMs (Qwen) and English LLMs (GPT-4) really do have the same values? The authors claim that Chinese LLMs score (quantitatively) significantly higher on cultural rankings, though another conclusion is that LLMs are ‘…not perfect representations of the cultural values of development contexts…’. In my eyes these are slightly conflicting. So what is happening here?
I suspect that datasets have a lot to do with it. As is common and now an encouraged direction, LLMs are being trained with synthetic datasets derived from other LLMs on the Pareto front of cost-to-performance, depending on how much you value volume over quality. The implication is that unless you go and collect a large amount of ‘virgin’ data (arguably this is now impossible), you are building on the foundations that previous LLMs have constructed, and implicitly, the values contained within them. Similar to how all modern compilers stem from the original A-0 compiler by Grace Hopper.
For a company like Deepseek, this poses an interesting question. If you value money, pursue what people will buy at breakneck speed. Use all the foundational work available to you and built a product that is so cheap and so effective that market forces takes over. Then you can worry about values. But for now, assuming that geopolitical forces at play are using LLMs like pawns on a chessboard, models like Deepseek are built on Western foundations. While OpenAI may take a temporary minor financial hit because of a potentially reduced market share, the game was set in motion a few years ago now, and it will be difficult to untangle.
There is a way out for Deepseek and its hypothetically value-driven creators. The model is cheap and good enough that large synthetic datasets will be created from it. By shifting the dial in favour of your own beliefs, or augmenting your model with your own value-driven data, it may be possible to shift the dial against Western values. There are glimmers of this seen in the tweet above which I will re-present.
However, the game is being played continuously, not turn-by-turn. By announcing huge amounts of funding for data centres such as Stargate, the West is aggressively attempting to not only win this race over the values of future LLMs, but remove the need for it. The sheer volume of compute is a hedge against other LLMs and a mitigation strategy against having to use the best data available on the open (geopolitical) market, by way of self improvement and reinforcement learning in a controlled setting. So has cultural victory been achieved? Can other nations untangle the roots that have grown? It will be a huge effort.
APPENDIX - EMPIRE OF SIGNS - ROLAND BARTHES
Recently I read Empire of Signs by Roland Barthes on the recommendation of Sunil Manghani, ahead of a trip to visit a friend in Japan. Barthes describes a fictional Japan, used as a device to counter Western ideologies and values. As follows:
Barthes broadly outlines a vision of Japan, and more generally the East, as a place where the sum of the parts don’t make a whole, but signify the act of the summation itself, the inbetween-ness of the parts. He makes this point by commenting on the writing system (composition of smaller signs), food (which itself exists in divisions that can only be divided further by chopsticks, never violently cut or destroyed), and through the act of giving gifts, wherein the packaging and act of giving a gift outweighs the contents. There is no centre, no answer, no true meaning to life in Barthes’ created world, it exists in the in-between spaces. Barthes describes the act of writing a Haiku like taking a single picture, without any film (or a memory card) in the camera.
We in the West want to impose a meaning to our models and their outputs, maybe stemming from our core belief of individualism, seeking to look inwards and attempting to assign a meaning or search for a soul. For those in Barthes Japan, the act of using an LLM, or the tokens themselves may have more importance. The instant that language is generated, but not the language itself, the process. I haven’t properly thought about the implications of this, but it leans into the creative process I am sure, and how LLMs can truly contribute outside of finding a creative solution. I’m sure Sunil and myself will discuss further, but speculatively, maybe the solution for the East and those without Western ideologies is to think beyond our established idea of ‘chatting’, implicitly with another being, a thing, a whole. We might not find it interesting or useful, but others might, and that’s OK.